书接上篇,这边将对漏洞相关细节进行一些分析:
漏洞相关
在博客写完差不多一个月之后。。。corelight中给出了该漏洞的相关检测方案,HuanGMz师傅提醒我,可能之前分析的点并不是真正的漏洞点,于是只好重新对漏洞点进行分析。。(幸好看博客和github的人不多,整整一个月的打脸( ̄ε(# ̄))新的分析也是师傅带着完成的,师傅发的文章写的比较有条理,这边就做一下分析经验学习。。
核心漏洞点(新)
用Bindiff能发现,以下五个API发生了明显的修复
1 | OSF_SCALL::ProcessReceivedPDU |
可以看到,后三个API开头为OSF_C,这个C肯定就是Client,一个9.8分的漏洞怎么会是客户端的漏洞呢,不可能的啦。结果是我才疏学浅了,真的是这个位置触发的。。

如何让服务器调用客户端API
这个原理与另一个漏洞的利用方式有关:CVE-2021-43893
这个漏洞利用了Windows的一个叫做Encrypted File System(EFS)加密文件系统的特性, 其中最关键的点在于,EFSRPC支持UNC Path,也就是可以以如下的方式来访问文件:
1 | \\10.0.0.1\Share\Test\Foo.txt |
而EFS可以通过发送RPC请求来将服务器侧上的文件下载下来,详情见此
概括来说,当我们发送一个EfsRpcOpenFileRaw请求,并且此时包含有UNC路径的时候,服务器就需要向一个UNC中指定的路径进行数据请求访问。该漏洞提到的一个渗透工具PetitPotam会利用这种简介请求来获取受害服务器的NTLM hash,而这个过程其实也是一个RPC。也就是说,利用这个思路,我们可以让受害者主机由服务器的身份变为客户端。相对于服务端,客户端的API往往会相对脆弱,利用这个思路就能将攻击面扩大到客户端API上!
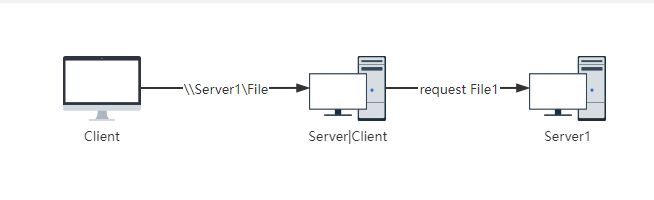
漏洞细节
这个点之后,回到看有问题的函数OSF_CASSOCIATION::ProcessBindAckOrNak:
1 | __int64 __fastcall OSF_CASSOCIATION::ProcessBindAckOrNak( |
函数主要用于处理RPC请求过程中,处理RPC的ack绑定的过程。这个绑定过程中涉及了两种类型的ack:
bind_ack,表示一个bind的请求被接受。此时会返回这种数据包,底层以数字12表示alter_context_resp,这个表示接受发生上下文变化的请求,并且返回该种数据包,底层以数字12表示
其中文档交代,两个ack的头部是一样的,这里贴出其中一个展示
1 | typedef struct { |
漏洞的核心触如下:
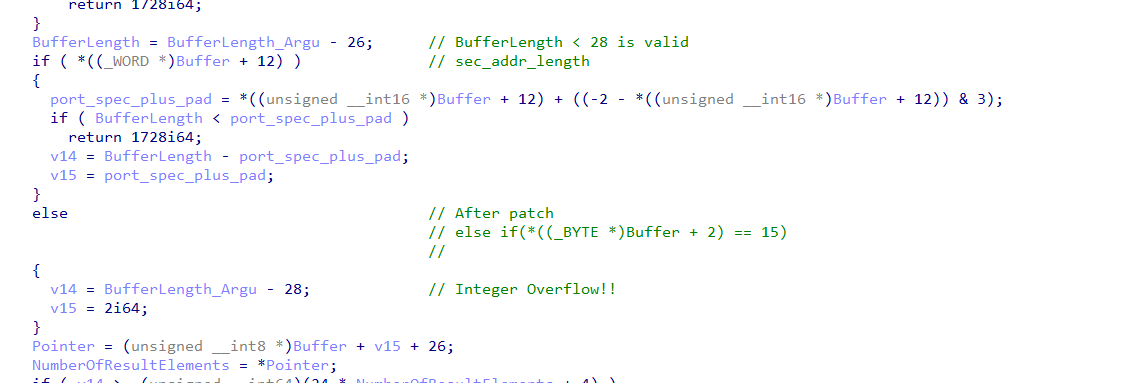
根据描述猜测,可能alter_context_resp的请求在请求头之后,会跟随一些描述变更情况的数据,而由于代码判断过程中,忘记检查type==15,也就是是否为alter_context_resp,此时如果请求头部的种类为bind_ack,并且我们发送的数据只有头部,此时BufferLength_Argu的长度就只有26,一旦进入else逻辑此时就会进行运算
1 | v14 = BufferLength_Argu - 28;// 0xfffffffe |
而v14作为长度,是一个无符号整数,其将整数溢出,从而导致漏洞的发生!
环境和PoC
由于这个漏洞触发需要服务器支持,这边准备的环境如下:
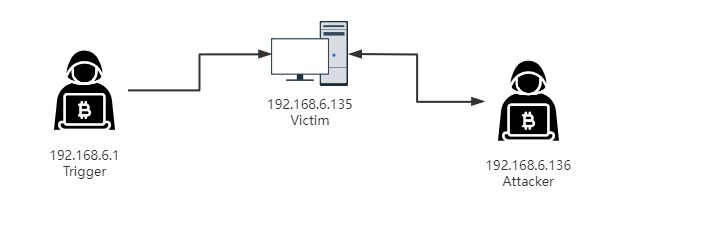
其中:
- Trigger机器上运行
PetitPotam,用于触发RPC - Victime机器上为老版本RPCRT4.dll,可怜受害者
- Attacker上运行一个假的SMB服务,并且返回畸形数据包
首先我们在Attacker机器上起一个假SMB服务
1 | from impacket.smbserver import SimpleSMBServer |
注意的是,这个/test/path/for/smb是需要真实存在的,包括路径下一定要有SMB请求的文件,不然的话RPC请求会失败,从而无法进入bind_ack的逻辑。
同时,可以参考
corelight中的截图,将impacket的rpcrt.py中,DCERPCServer的bind函数进行修改:
1 | def bind(self, packet, bind): |
然后在Trigger机器上运行PetiPotam,运行指令如下:
1 | python petitpotam.py -pipe lsarpc -method DecryptFileSrv -debug "user:password@192.168.6.135" "\\192.168.6.136\realfile |
之后就能观察到相关的请求数据包:
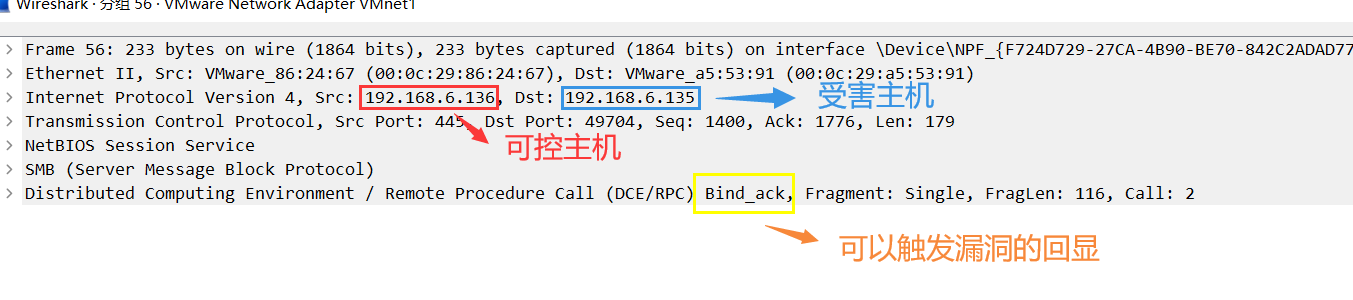
此时就能触发漏洞!
BSOD?
然而漏洞触发之后,也不一定能触发BSOD,理由在这:
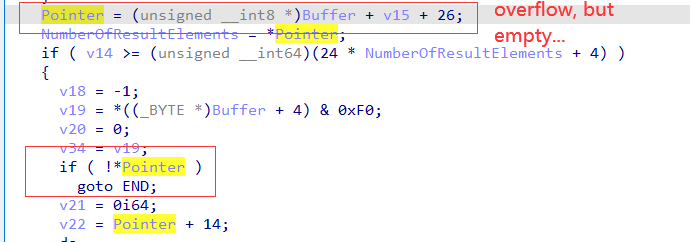
尽管我们触发了漏洞,但是在之后的逻辑中,会先检查Pointer指向的内容是否为空。虽然Buffer的理论大小为26(也就是bind_ack头部数据大小),而此处的Pointer已经是一个越界访问,但是这个地方的内容实际上并不是我们可控的,所以会在一开始的check就被扔掉。。。
不过如果有办法能够控制目标机器中的堆内存,进行堆风水排布的话,说不定还是能够实现控制的,这个就有待进一步研究了。。
核心漏洞点(旧)
Patch修复的位置有如下两个位置可以参与漏洞利用:
1 | OSF_SCALL::ProcessReceivedPDU() |
首先我们可以看到第一个函数ProcessReceivedPDU,这里提到了PDU,这个玩意儿的名字是protocol data unit的缩写。微软官方的解释是:
RPC PDU: A protocol data unit (PDU) originating in the remote procedure call (RPC) runtime.
在这里详细的介绍了这个概念。这个概念在之后我们会进一步探究。
这位大佬详细的介绍了自己的分析思路,可以先跟着他的操作进行初步学习。通过学习分析思路会发现,视频中无法进入的分支是因为存在一个需要设置的标志位

通过逆向分析可以发现,这个标志位其实标志的就是上文提到的Pipe对象。只有当Server端的接口为Pipe接口的时候,这个位置才会被置为1。根据观察分析,因为pipe对象允许类似队列Buffer的工作机制,所以可能需要有单独的处理逻辑。而正是没能正确的处理队列逻辑,导致了漏洞的出现。
不过在Server端存在Pipe的情况下,我发现代码会反复的陷入这个位置:
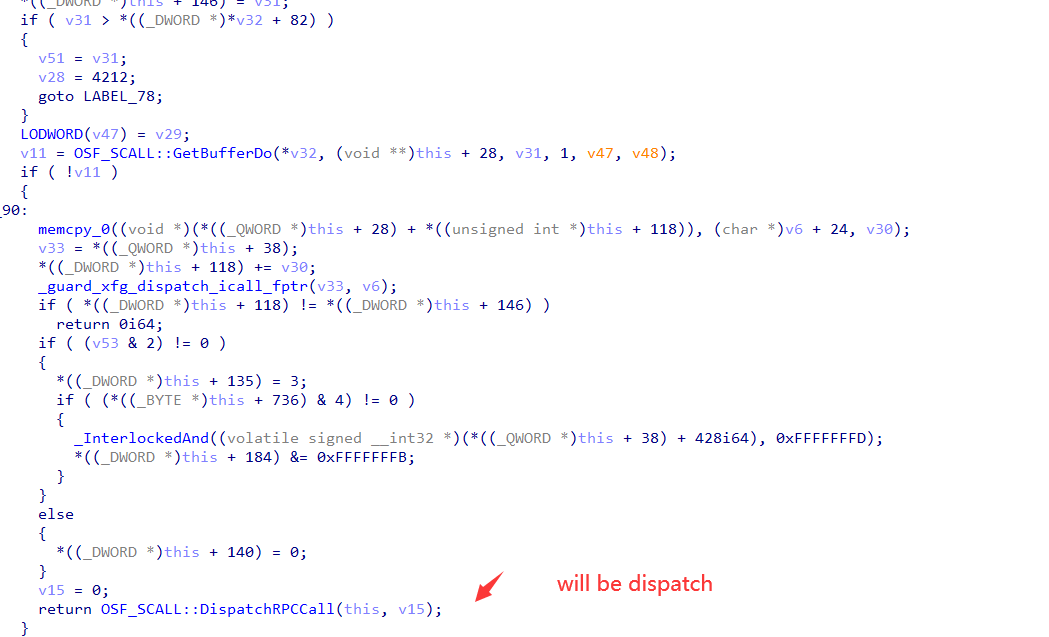
这段逻辑的工作类似于:将传入的Buffer进行解析,如果满足条件之后,则进入DispatchRPC的逻辑,而当进入这个分支之后,代码就不会回来了。为了搞清楚这个逻辑,这里需要深入理解一下发送的数据包格式:
PDU格式
PDU的格式可以看这里。这边我们选取几个重要的讲一下:
1 | typedef struct { |
上述为Request PDU格式,也是当我们Client像Server发送请求,包括Server pull 来自Client的数据的时候,RPCRT4中使用的一种格式。格式中有几个重要的成员变量
pfc_flags:表示当前请求的类型,目前常见的有PFC_FIRST_FRAG以及PFC_LAST_FRAGpacked_drep:用于表示当前PDU请求中每个元素的类型。frag_length:用于表示每个fragment切片的大小alloc_hint:用于描述当前建议server端分配的数据大小opnum:由于描述当前操作的是Server的哪个接口
在request之后,就会紧跟着body,也就是发送的数据结构体。
我们将之前文章中编译的的Pipe实际的例子跑一下看看:

可以看到这边使用的是DCERPC协议,其实就是OSF-DCE Open Software Foundation Distributed Computing Environment定义的一种协议,包括上文提到的PDU也在其中。然后我们看到数据包中有记录First 和 Last数据包,就是由flags控制的
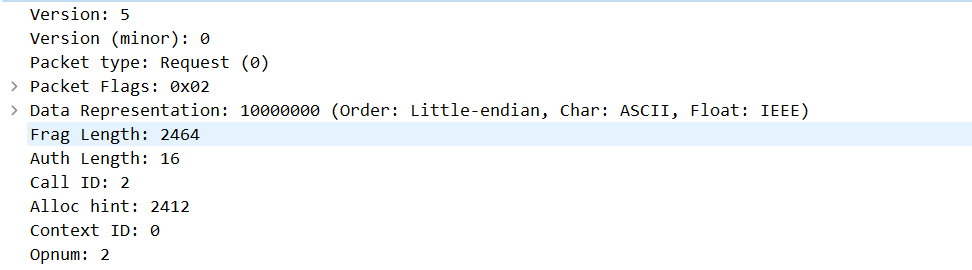
这边可以看到发送的数据包在发送过程中,会给出frag_length和alloc_hint。然而会发现两者长度不完全一致,这是由于alloc_hint用于描述建议server端用于存放NDR数据的大小。这个大小不包含当前rpcconn_request_hdr_t的大小。而frag_length表示的是单次发送的fragment大小,其包含了rpcconn_request_hdr_t(24字节),当存在认证的场合,还需要分配对应的认证用context。两者的大小不一定相等(这也导致了后方漏洞的出现)
NDR Network Data Representation
在数据传输的时候,RPC会使用NDR来描述当前传输的数据类型。NDR可以简单的理解成一个TLV协议的结合体。RPC内置的属性都可以用NDR进行操作。
这里我们关注Pipe的NDR类型
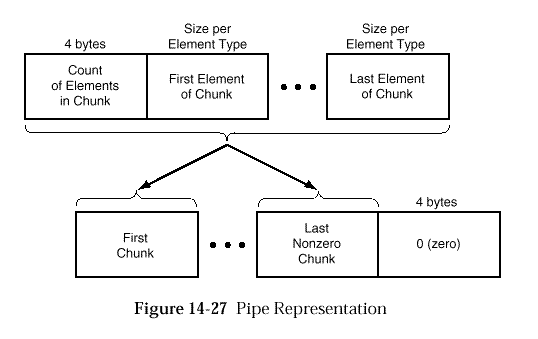
其官方描述如下
NDR represents a pipe as a sequence of chunks, not necessarily all containing the same number of elements. A chunk can contain at most elements of the pipe. The number of chunks is potentially unlimited. NDR represents each chunk as an ordered sequence of representations of the elements in the chunk, preceded by an unsigned long integer giving the number of elements in the chunk. The final chunk is empty; it contains no elements and consists only of an unsigned long integer with the value 0 (zero).
从描述中我们可以得知:
- Pipe中其实最多可以传输个元素
- 最后一个元素通常为空
这边注意,Pipe中,前四个字节存放的是元素的数量,而非总共的长度,这点要注意。。
1 | 比如说Long对象,理论上chunk=1的时候,NDR的总长度为4+4 = 8 |
当check不满足的时候(后文会根据chunk的数量申请内存大小。如果内存太小发生越界,则拷贝不发生,并且抛出bad_ndr的错误)
再RPCRT4中,管对这个NDR解析的过程叫做Unmarsharl,大致可以理解成反序列化
重回ProcessReceivedPDU
根据前文的前置知识,我们知道发送的PDU数据中,存在一个叫做Fragment 分片的概念,结合文档中提到的分片发送,不难猜测,整个漏洞的核心原因应该是分片Fragment发生合并的时候导致的整数溢出。通过调试可以还原部分的数据结构,其中ProcessReceivedPDU函数中的漏洞函数如下:
1 | FragmentLength = Size; |
可以看到,这边将PDUBuffer加入了一个queue中,并且将每次传入的FragmentLength叠加到当前对象的TotalLength成员变量中,这边忘记检查当前的分片长度是否溢出,从而导致存在了整数溢出。可以猜测,后文应当存在一个逻辑,将此处压入的Buffer数据包取出,然后送入另一个buffer中,而由于这边算的长度存在问题,从而导致了越界写的问题。
然后我们回到前文提到的另一个问题:代码流程无法进入漏洞触发点,而是提前就进入了DispatchRPC,这段其实和分发逻辑有关,这边存在几种情况:
分包逻辑1:快速处理逻辑
当我们发出的数据包为PFC_FIRST_FRAG与PFC_LAST_FRAG flag同时设置的时候,会进入前文的快速分发逻辑,导致不会发生分片
1 | if ( (Flags & 1) != 0 ) // PFC_FIRST_FRAG |
分包逻辑2:分包,但是大小足够
当我们发出的数据包有多个,其中第一个为PFC_FIRST_FRAG的同时不为PFC_LAST_FRAG的场合,此时会判断allocHint大小判断
1 | alloc_hint = *(Packet + 4); |
如果此时发包不足allocHint大小,意味着此时ServerBuffer足够缓存数据,于是直接拷贝到缓存的Buffer中
1 | if ( !OSF_SCALL::GetBufferDo(*CurrentBinding, &this->DispatchBuffer, AllocHint, 1, v49, v50) ) |
并且如果包为PFC_LAST_FRAG,则单次传输结束。
如果使用微软官方提供的sample,是无法触发漏洞点的,因为官方的allocHint大小每次都是同时存在PFC_FIRST_FRAG和PFC_LAST_FRAG导致每次都会立刻进行Dispatch,最终导致错过漏洞触发条件。
分包逻辑3:触发RPC分发逻辑,但是同时发生分包
总结一下,为了能够触发漏洞,我们需要
- 将发送的数据包分为
PFC_FIRST_FRAG和多个数据包,最后跟着一个PFC_LAST_FRAG allocHint字段给出的buffer大小需要不足以承受之后所有的数据包
当满足上述两个条件之后,当第一个数据包进入了DispatchRPC,程序就会进入数据处理逻辑,同时由于此为多线程处理逻辑,Server还会接受之后到来的数据包,此时由于
- 已经有数据包进行了分发
- 申请的Buffer大小已经消耗完成
所以此时只能将数据包压入队列,等满足条件再进行数据合并,于是能够进入后方的PutQueue逻辑:
1 | FragmentLength = Size; |
于是能触发这段逻辑。
再实验的时候,这里使用了python脚本,以及引入库impacket.dcerpc.v5.rpcrt进行数据发送,但是这个库会将AllocHint设置成正好能够放得下所有请求的NDR大小总和的数值,导致最后都会被一次性发送给DispatchRPCCall,导致无法进入后方的逻辑。于是这边需要手动修改这个包的处理逻辑(直接修改库中的代码才行),将allocHint的大小改成每次发送的fragment的实际大小即可(一般来说,fragment因为存在头部数据大小(32bit为24字节)的真实大小会略大于allocHint,可以通过wireshark进行调整)
NDR格式Check
再尝试发送请求的数据的时候,一直有一个bad_ndr的错误。后来经我观察,发现RPCRT4并没有严格按照之前提到的规范来实现Pipe。再NdrReadPipeElements中会调用NdrpReadPipeElementsFromBuffer进行数组数据的读取,其中
1 | if ( !(*(*a1->pipeHelper + 96i64))(a1->pipeHelper, pipe_message, &UnMarshalLength) )// NDR_PIPE_HELPER32::UnmarshallChunkCounter |
完成反序列化之后,这里的Chunk数量居然要和这里的minSize和maxSize比较。这两个变量的含义是Pipe中能够存放的最大元素。minSize自然为0,而maxSize居然只有短短的0xffffff。 多少有点小了吧,文档原文不是说可以很大的吗 ,于是这边我们需要严格按照如下的格式构造请求的数据体:
1 |
|
当我们的chunk大小合理之后,就不会被这边卡住了,函数的后方会调用NdrpPipeElementConvertAndUnmarshal,对这个Pipe中的每一个元素进行Unmarshal。
进入OSF_SCALL::GetCoalescedBuffer前的最后准备
根据观察,会发现不是每次NdrpReadPipeElementsFromBuffer调用完成之后,都能够进入OSF_SCALL::GetCoalescedBuffer。于是要来观察当前函数的触发逻辑:
1 | if ( (a1->field_12 & 0x20000) == 0 ) |
可以看到,当前函数的调用中,有一个非常关键的检查(据观察,后两个flag检查基本都是通过的)就是
1 | if ( readElem ) |
也就是说,只要我们能够让readElem的值为0,我们才能进入NdrPartialReceive。这个值是在NdrpReadPipeElementsFromBuffer中被设置的。于是这边跟如这个函数。函数使用类似状态机的代码进行维护
1 | state = a1->state; |
state=1的时候。会尝试读取NDR数据段中的chunk字段,并且检查chunk的长度是否在规定长度内。(这点就要吐槽了一下,规定中这个chunk应该是无限长度的,这个地方居然有maxsize。。)如果ChunkNum(也就是chunk字段)不为0的时候,进入状态1:
1 | Buffer = a2->Buffer; |
这边首先会计算ContentBufferLength,这边的a2->RpcMsg->Buffer其实就是未处理过的Buffer,指向我们发来的NDR数据(含头部),a2->Buffer是NDR数据(不含头部)的起始地址。这个算法就能计算出来NDR body的大小。然后取出来的ElemSize表示的是pipe数据结构中,每个元素的大小。如果我们传输的是long结构体,这个地方大小就是4。之后就会进入拷贝的前的检查逻辑:
1 | if ( !readReadLength ) |
这边会根据当前数据的padding,当前缓存的大小,以及指定要读取的数据大小,选取一个合适大小的BufferLength,并且最后调用NdrpPipeElementConvertAndUnmarshal来进行pipe的数据反序列化。当读取完成之后,会减小readReadLength的大小,并且iang实际上读取出来的数据加到hasReadElem_ptr,也就是我们前文提到的hasReadElem中。
可以看到,只要数据能够读入的场合,基本上这个hasReadElem就会被设置。所以只能锁定在之前提到的一个位置:
1 | ContentBufferLength = LODWORD(a2->RpcMsg->Buffer) + a2->RpcMsg->BufferLength - LODWORD(a2->Buffer); |
虽然这里说【一般不满足】,但是不妨设想一个场景:如果在反序列化的过程中,如果此时的pipe的头部已经来到了,但是body却没有及时传输过来,此时理论上就不应该进行反序列化。从代码上也能看出,如果头部正好过来了,但是body没有过来的场合,此时甚至无法满足ElemSize>ContentBufferLength,于是就会进入后文提到的NdrPartialReceive,从逻辑上讲就是先将分片进行合并,然后再对其进行数据解析。
不过经过POC测试,由于分片的时候,长度会增加4字节,基本上Buffer的长度维持和分片长度倍数的情况下,都能满足:
1 | def format_fragment_data(data, frag_size): |
关键点 OSF_SCALL::GetCoalescedBuffer 漏洞触发
这个函数理论也被微软进行了修复:
1 | fForceExtra = a2->RpcFlags & 0x4000; |
可以看到,v10这个变量再v7被设置为Extra的时候,能够再次叠加一个Buffer,然后在之后的逻辑中:
1 | v16 = QUEUE::TakeOffQueue(&this->osf_scall258, &Size); |
会将之前Queue中的数据包和长度一并取出来,拷贝到对应的Buffer中。此时如果发生过整数溢出v17长度必定不可控,而且内存还是由我们控制的,是一个很容易利用的漏洞。
无法造成的溢出?
诚然,可以看到这个程序中调用了函数
1 | OSF_SCALL::TransGetBuffer(v9, &v23, v10 + 24) |
这边的v10就算无法触发v7,进入Extra状态,理论上也应该还能叠加一个我们前文控制的receiveLengthVuln。然而再实际测试过程中,我发现几个点:
FragmentLength本身存在长度限制(ushort类型,长度最长只能为0xffff,而且实际上设置不了这么大)- 当进行多个数据包发送的过程中,每次数据包发送累计到一定的数量的时候,都会强行进入
GetCoalescedBuffer。再开始的几个包肯定不足以造成溢出,并且最重要的是再GetCoalescedBuffer函数末尾,存在如下的逻辑
1 | v8->Buffer = v12; |
一旦进入这个函数,则receiveLengthVuln就会被置为0.。。。从而造成无法溢出的问题。然而再这个函数的外层,存在这样的逻辑:
1 | result = OSF_SCALL::GetCoalescedBuffer(this, a2, Extra); |
如果BufferLength >= Size,则会被返回。。。
漏洞点触发关键
但是仔细看函数的外部,会发现这个OSF_SCALL::GetCoalescedBuffer其实存在被多次调用的可能:
1 | if ( this->receiveLengthVuln <= *(this->Connection + 92) )// Connection->MaxFrag |
从逻辑上看,a2->BufferLength存放了之前累计传入的Buffer的总长度。一旦传入的长度没能达到Size的大小,此时的Buffer就会依然被认为是ExtraBuffer,此时会进入EVENT::Wait(&this->pvoid2C0, -1);,此时程序流会重新交给ProcessReceivedPDU,让程序能够对数据包进行进一步的读取。当满足一定的条件,这边的Event会被重新唤醒,此时之前存入的a2的Buffer就能一次又一次的叠加到当前Buffer上面,同时BufferLength也会反复的进行数值叠加。如果能够控制这个值,就能够实现发送大量重复的数据包,从而实现整数溢出!
1 | GetCoalescedBuffer -> a2->BufferLength = Receive1 -> a2->BufferLength < Size, it will wait -> ProcessReceivedPDU -> a2->BufferLength += Receive2 -> a2->BufferLength < Size, it will wait ...... |
Size到底是啥
这个要回到之前Pipe教学的时候提到的BigPipe概念。这个Size其实表示的当前pipe中能够存放的未合并的Buffer大小,这个大小在一开始由MDIL生成的文件中的xxx_s.c中的FormatString结构体中可以被修改:
1 | /* 8 */ 0xb5, /* FC_PIPE 对应FC 也就是pipe的魔数*/ |
也就是这一段。这里的Size就是我们之前提到的,检查GetCoalescedBuffer调用结束后,读到的BufferLength是否过大的Size,可以看到这个地方仅为4(默认大小),并且如前文提到的,这个值会在NdrReadPipeElements中被设置为0x40。此时可以发现,其大小最多仅为Short,如果我们把pipe符号位设置成0x83,那么这个字段则可扩展为Long,此时就能扩展数据,让其变成一个非常大的值。当这个Size足够大的时候,我们上文提到的GetCoalescedBuffer就能被反复调用,于是造成整数溢出的问题。
关于ProcessReceivedPDU和GetCoalescedBuffer的时机
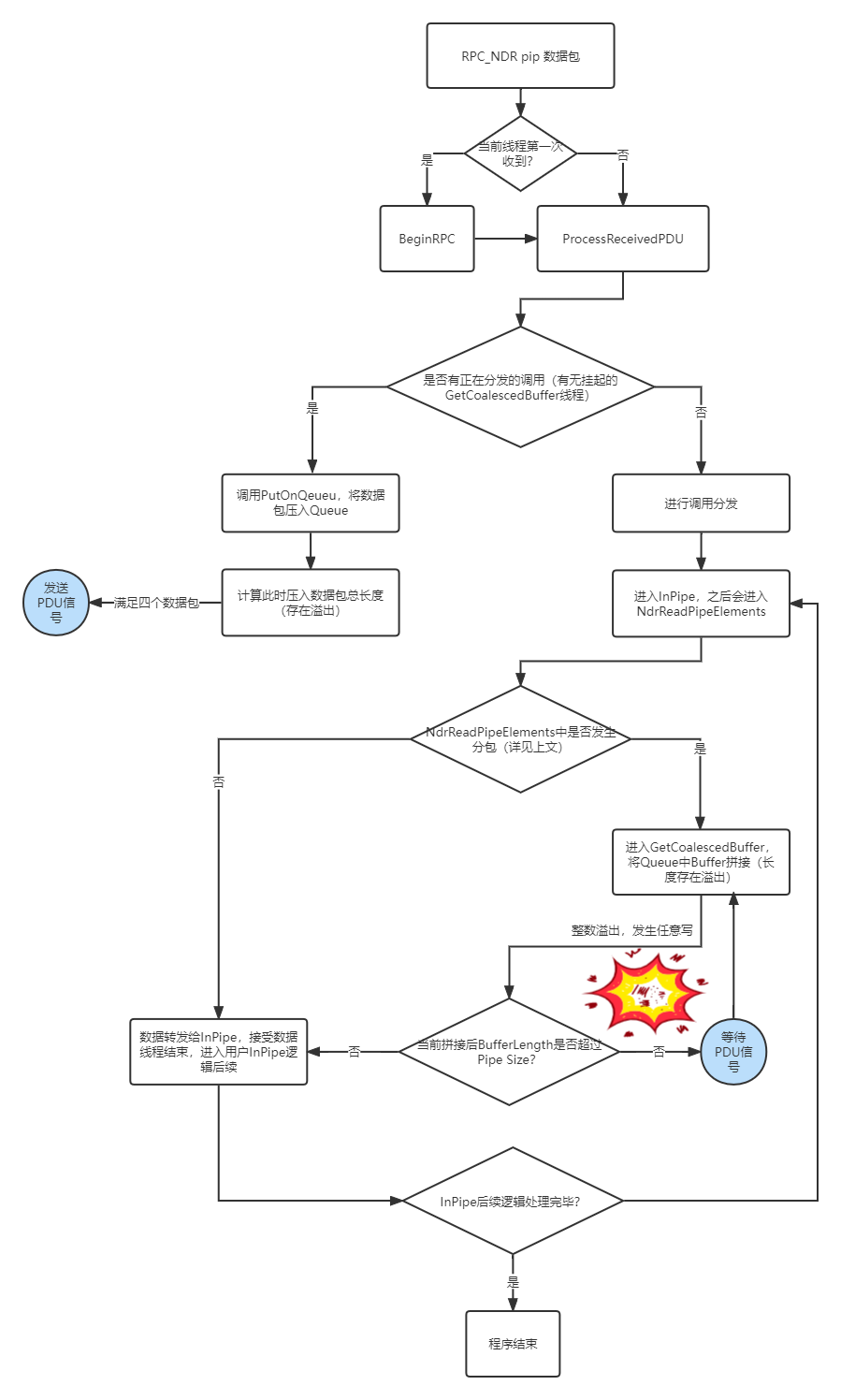
现在已经能够知道如何触发漏洞点,所以,现在需要具体的确认这两个函数的调用时机。整个过程比较长,这边整理一下大致的调用逻辑如下:
- 第一次进入
ProcessReceivedPDU,接受大小正好的包,进行dispatch。 - Dispatch过程中,会首先对Pipe进行初始化,(没错,这个时候才会初始化pipe对象,也就是调用
InitPipeStateWithType系列函数),之后会将RPC发送到InPipe(一个Server侧编写的函数,这边取个简单的名字) InPipe通过调用NdrReadPipeElements,NdrReadPipeElements调用NdrpReadPipeElementsFromBuffer对数据进行读取。- 当
NdrpReadPipeElementsFromBuffer中,当前NDR中Pipe的元素耗尽的时候(其实据观察,应该是发生了分片的场合),发生NdrPartialReceive调用,表示当前需要将之前的缓存的Buffer读出来 - 当
Receive调用的时候,此时由于未收到PFC_FRAG_LAST,调用未完成,于是进入Default分支,从而进入GetCoalescedBuffer分支。 - 再分支中,会依次将之前ProcessReceivedPDU读入的Buffer一次次记录下来。注意,
MaxFrag只是用来控制Fragment的合并,不会导致当前叠加的退出。 - 所以可以存在如下的的场景:
假设size的大小合适的话
- 满足
ProcessReceivedPDU接收到的包大小控制合适 - 满足
GetCoalescedBuffer中判断的Size大小合适的话
当发生一次GetCoalsedcedBuffer就能造成溢出
8. 当接受过一次的包,如果满足大小小于size,此时的GetCoalescedBuffer线程会调用Event.Wait(-1),此时会导致其他线程被激活,从而能够继续调用ProcessReceivedPDU,然后就能回到1调用。
调用示意图如下:
漏洞总结:
触发条件
- RPC Server端存在一个Pipe类型的接口(这个Pipe是RPC里面定义的Pipe,不是命名管道那个),不妨叫做RPC_PIPE1
- RPC Client往RPC_PIPE1发送【较大数据】,数据大小超出【client端设置的max_fragment】
- RPC Server端会收到分片的数据包。当RPC Server收到数据包之后,存在两个判断值
1 | Alloc Hint <- Client推荐Server分配的内存大小,可以远大于 Frag Size。限制最大为0xffffff |
当某次发送FragSize==AllocHint的时候,当前数据包被处理。之后的数据包进入缓存状态
4. 缓存状态下,存在一个缓存buffer(漏洞点)其长度为BufferLength。每次数据包进入缓存状态之后,都有
1 | PutOnQueue(buffer, bufferLength); //临时存放到某个队列里面 |
上述BufferLength存在整数溢出。
5. 当接收到最后一个数据包(标志位由Client设定)的时候,进入GetCoalescedBuffer函数,此时会申请一个BufferLength大小的堆,然后将之前压入Queue的数据包取出来,依次拷贝进去
理论上只要我们发送的fragment够多,BufferLength就会发生整数溢出,变成一个很小的值,此时我们取出来的数据包就能实现一个堆溢出攻击
POC?
实际上,一趟分析下来,感觉整个漏洞利用有一点点理想化了。可以看到如下的限制
服务端
- 服务端需要使用了Pipe结构
- 服务端需要主动修改Pipe Flag。实际上这个Flag从官方文档中并没有提到,而且再官方给出的编程说明中,也往往是推荐直接使用
midl进行生成,这个时候根本就不会修改将当前标志位修改成可以被利用的状态
网络状态
从分析来看,至少需要溢出DWORD大小的数据,而关于fragment设置的大小,虽然规定大小是short大小,但是实际上尝试的时候发现,微软客户端会限制发送大小,单次只能发送5000字节,而如果要造成DWORD的数据发生溢出,至少要发送10000000左右个数据包才能造成溢出,而且RPC的库中,通常存在超时认证,也就是发送如此大数量的数据包,同时还不能因为超时被kill,感觉其难度非常的大。。。
总结
总的来说,这趟分析下来,感觉攻击利用的难度非常大:非常极端的服务器配置,非常高性能的请求要求,让人有点点不解为啥价值9.8的分数。。。可能是由于我能力比较差,只能分析到这个程度了,要是有大佬能够愿意指点就好了。
PS:全文提到的测试的代码源于微软官方仓库,相关的代码可以这里下载
参考链接
https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-rpce/543b0019-e8ea-4b58-b4d5-324fd692966d
https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-efsr/ccc4fb75-1c86-41d7-bbc4-b278ec13bfb8
https://pubs.opengroup.org/onlinepubs/9629399/chap12.htm
https://pubs.opengroup.org/onlinepubs/9629399/chap14.htm
https://www.youtube.com/watch?v=GGlwy3_jVYE
https://www.rapid7.com/blog/post/2022/02/14/dropping-files-on-a-domain-controller-using-cve-2021-43893/
https://corelight.com/blog/another-day-another-dce-rpc-rce