本文首发于奇安信攻防社区 https://forum.butian.net/share/2770
Scrambled-up
题目感觉是一种新型的混淆模式,又可能是一种常见的某种程序分析或者动态执行的过程。我咨询了周围一些朋友,大家都只是觉得眼熟,很可惜不能找到它的真身
主办方最后给出了程序的源码,是经典的函数式编程。根据研究应该是某一种lisp的方言,感觉想要复现应该是很困难的了。。
这个文章前半段会讲一下大体的分析思路,如果只想看整体逻辑的话,可以跳到中间部分的程序架构介绍开始
初探程序
题目只有一个elf,当把程序运行起来后,可以看到其大部分的逻辑都很普通,除了那个mmap了超大内存的地址,以及两个奇怪的函数(这两个函数我已经重命名过)
1 | signal(SIGSEGV, invalid_flag); |
程序初始化 read_inst
这个read_inst中会从两个全局变量中读取数据。他这个读取过程会使用两个全局变量inst_edge和inst_code。在这里,程序会分别将这些数据读入,并且更新一个数组,这里为了方便描述,下文称为Block。以下是修改后的大致逻辑:
1 | // 首先会遍历所有的inst_code |
根据这里的逻辑,我们可以猜测如下的三个概念:
- Inst:记录一个类似二进制在磁盘上存储的状态,表示当前的一些运行基本信息
- Edge:记录了两个不同的二进制块之间的关联
- Block:类似于加载到内存中的程序块
这三个结构体大致如下:
1 | struct Inst |
第一次看到这些结构体可能会难以理解,我们会在文章后面逐步介绍这些结构体是什么。除了这些关系外,我们可以观察到,不同的Block(Inst)会被Edge关联起来,其关系如下:
1 |
|
可以看到,每一个DSTBlock中,会被多个SRCBlock注册。其中每一个SRC被注册的时候,会将对应的arg的地址放到DST中的slot中。每一个arg的序号不固定。
其次,我们可以注意到在Inst和Block末尾能看到一个叫做Var的变量:
1 | struct Inst |
每一个Block中可能包含一个有效的属性变量。这个属性的定义如下:
1 | struct Var |
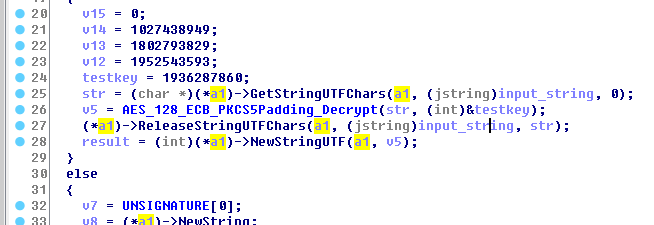
成员变量解释如下:
var_type:当前变量的类型。1的时候表示当前var_or_ptr中存放的为指针,2的时候表示var_or_ptr中存放的是变量本身,0的时候表示当前值为无效值var_or_ptr:当前变量的值var_length:当type为1的时候,表示指针指向的内容长度
总结一下,初始化过程中会发生如下的流程:
- 读取磁盘中的Inst,将其放入Blocks数组中
- 读取磁盘中的Edge,将不同的Blocks的arg与另一些Blocks的slot关联
解析Block parser_inst
在执行流中,程序执行过程如下:
1 | new_lines = calloc(lines_number, 1uLL); |
整个程序流执行的时候,有如下的检测逻辑:
- 如果argc为0的话,进入
exec_inst逻辑 - 如果argc不为0的时候,检查argv是否已经被完全初始化(不为空),如果彻底初始化,进入
exec_inst逻辑 - 程序运行完成之后,会检查是否执行到最后一个块,如果执行到最后一个块,但是并未每一个块都执行过,程序将会直接退出
这里将会埋下程序执行流的第一个疑问:argv将会在哪儿被初始化?
执行部分 exec_inst
这个函数中,存放了11个不同的函数:
1 | __int64 __fastcall exec_inst(NewInstr *a1) |
程序会通过将9个不同的函数放到栈上,并且根据Block中的exec_type指定我们需要执行的函数类型。我们在这里将这些函数定义为ExecFunc。这里总结一下不同的type对应的函数功能
| type | 函数作用 |
|---|---|
| 1 | 将所有的argv相加,将答案赋值 |
| 2 | 将所有的argv相乘,将答案赋值 |
| 3 | 将var位置的block赋值 |
| 4 | 调用一个函数指针,并且将调用结果赋值 |
| 5 | 如果argv[0] == 0,则使用argv[1]赋值,否则使用argv[2]赋值 |
| 8 | 检查flag是否正确 |
| 9 | 调用read函数,将flag读入全局变量中 |
| 10 | 将两个指针指向的内存合并到一个新的内存中 |
| 11 | 获取argv[0][argv[1]]的值,并且赋值 |
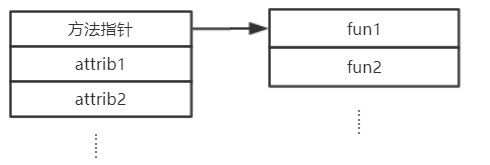
这里可以看到,反复提到了一个叫做赋值的操作。这个操作具体在做什么呢?我们选择其中最简单的类型3assgin为例子看一下:
1 | void __fastcall assign(NewInstr *a1) |
这边可以看到,程序在运行过程中,会将slot中存放的内容作为指针取出,并且将从var中取出的数值赋值到指针中。这个就是前文提到的赋值概念。更加形象化的描述的话,这个赋值过程如下:
- 程序进入
exec_inst,执行block指定的一个函数 - 此时,取出
block中所有的argv(在之前我们限制了argv一定要都处于被初始化的状态,而且类似assign过程是不需要参数的) - 执行操作,获得一个计算结果
- 从当前
block的slot中取出所有的指针,并且进行赋值
1 | for(int i; i < block->slot_cnt;i++ ) |
至此,我们可以知道当前Block的几个特征
- 程序在运行过程中,一个Block的输出会影响其他Block的输入
- Block通常会拥有多个参数,但是所有的参数都要其他的Block作为输出赋值,除非当前Block的
call_type为3,此时block不拥有参数,只会有赋值动作 - Block的输入参数不会被修改,单个Block类似于pure function
exec_type 4 – 新的关键函数
程序在运行的时候,会发现这个exec_type:4还蛮关键的,看到其函数如下:
1 |
|
可以看到,这边会将argv[0]作为输入,拷贝到全局变量addr中,然后将其他的argv作为参数传入到这个函数指针中。然而在逆向过程中会发现,代码中的数据段并没有任何地方存放了一个完整的函数。通过一些逆向我们能够知道,函数们似乎在最初都被加密了,所以只得让程序运行一段再回头看。这里给出call_type:4会执行的函数,为了与上文的ExecFunc区分,这里我们定义他们为CallFunc(函数名为我们自定义的)。
| 函数名 | 作用 |
|---|---|
| xor_all_argv | 将所有的参数异或 |
| or_all_argv | 将所有的参数或 |
| and_all_argv | 将所有的参数相与 |
| check_if_zero | 检查第二个参数是否为0,如果为0返回1,否则返回0 |
| get_index_from_input | 获取输入的第index参数,此时输入会传入该函数中 |
| reorder | 将输入(16字节)按照指定的顺序重构 |
| maze_step | 走迷宫函数,最后介绍 |
到这一步,基本上所有静态分析(其实也使用了动态了)能做的就都做完了,接下需要对程序进行一个宏观审视,才能进一步的分析整个逻辑。
程序架构介绍
分析了上面的执行流之后,我们发现这个程序的执行过程和传统程序不一样,甚至和传统意义上被混淆的程序有所不同。
传统意义上,我们的程序使用了是带有分支的执行流,例如:
1 | if(a > 0) |
从程序上来看,if..else..是两个完全不相关的逻辑,这就意味这程序本身是以执行流作为指导,比如说:
- 程序会因为传入的数据变化进入不同的分支,并非所有的逻辑都会被触发
- 程序执行的过程中,可能同一个变量会持续地被修改
- 程序地条件语句执行变化非常的丰富
即使是进行混淆(例如ollvm的扁平化),本质是基于执行流,即通过增加状态值,让程序跳转到不同的执行块上。这种编程方式我们临时性的定义为执行流编程
然而根据前面分析我们可以知道,本题有以下几个特征
- 程序运行为简单的线性,所有的逻辑都会被执行一遍
- 程序执行过程中,只有输入变量和输出变量,并且输入变量恒定不变。当程序有需要修改输入变量指向的位置地时候,会将输入变量本身输出到另一个代码块,然后再执行
- 程序条件判断很简单,只有判断0和非0两种情况
根据搜索,这种被称之为数据流编程(Dataflow programming)也就是使用数据流作为串联整个程序地核心。
将这两个对比可以得到如下地结果
| 执行流编程 | 数据流编程 |
|---|---|
| 根据输入情况,并非所有逻辑都会执行(不考虑exit等系统调用) | 无论输入如何变化,所有逻辑都会被执行(不考虑exit等系统调用) |
| 程序中的单一变量可能被修改 | 存在输入和输出变量,输入变量一定不能被修改 |
| 条件语句较为丰富 | 条件判断单一 |
题目分析
题目初步分析
这里对比以后,我们会发现这个题目存在以下难题:
- 我们不能像以前一样简单的模拟程序,从而还原当前程序。常见地去混淆之类的技巧就是通过模拟运行(或者真实运行)重组当前执行流,然而当前程序执行流均被展开。比如说for循环中的i在这个数据流中完全被展开了,不存在形如(BlockA -> BlockB -> BlockA)这种执行顺序。因此循环和判断语句需要完全凭借经验进行转换。
- 即使尝试进行执行流还原,粒度也会非常细。每一个BlockA最多只会执行一个简单的函数(除了maze_step)这样一来我们就很难像常见的逆向题一样,根据一些特定的特征函数对数据进行还原。
- 程序的变量传递是随着程序进行的。不同于执行流,这个数据流程序的变量一直都是持续的传递和组合,而传统的执行流程序很多时候并非真的需要完全解密(除了某些SMC程序)往往找到条件判断|加密这两部分逻辑,再在关键位置进行dump,就能够还原原先的逻辑。即便是类VM的程序,也能够根据对应的VM所指令,将指定的变量按照对应寄存器之类的处理还原,最后能够还原出整体逻辑。然而当前程序本身粒度非常细,并且变量传递非常频繁,这就需要人为主动的根据逻辑分析哪些变量是无需考虑,哪些变量需要我们持续追踪。
分析了上述难点后,我们发现,想要解出这道题,需要满足如下需求:
- 尽可能地打印原始的数据流块,并且需要还原变量传递的关系。虽然粒度非常细,但是通过审计和猜测,可以得到部分数据块之间的关系。
- 在尽可能程序运行结尾处进行内存dump等工作,这样能保证所有变量已经完成了传递。这种数据流虽然缺失了执行跳转,但是从另一个角度说,在结尾处,所有的逻辑都会被执行。这就意味着即便是输入出错,我们也能获取完整的逻辑。
- 每一个Block都有多个参数,参数的赋值顺序来自于其在Edge中注册的顺序,越早注册的argv下标越大,需要结合edge弄明白变量来自于哪个block。
阶段一:数据流dump
为了尽可能的获取数据,我们可以在ExecFunc8,也就是确认flag是否正确的函数处下断点,当程序能够运行到当前位置的时候,说明所有的Block解密部分以及数据传递已经完成。

此时,内存中的数据如图:
此即为Block所在的堆。于是此时我们可以尝试dump完整的运行中Block数据。根据当前的偏移,计算起始坐标:
1 | 0x7FABE02BC0D8(current_addr) - 0x48(sizeof(Block1))*0x1191(line) |
同时,我们找到edge对应的位置:

此时,我们找到了关键的Block和对应的关联Edge。编写脚本,将所有的执行流dump下来:
1 | import idc |
其中的函数表为我们单独在IDA中分析得到的结果。之后就能得到一个处理后的Block数据关系,由于多达0x149d个block, 这里选取部分内容展示:
1 | [0x7f01023890a0]Block[0x402]: |
阶段二:flag有效性检查一
在Blocks在逆向过程中,会发现存在大量的重复逻辑:
1 | [0x7f0102389208]Block[0x407]: |
例如上面这段0x407~0x40b和上面贴出来的0x402~0x406非常类似。并且我们可以观察到,0x403获取的值为1,0x408获得的值为2。总结一下特点:
- 逻辑极为相似
- 存在固定值递增
几乎可以断定,即便是从不同的Block取出来的值,这些值应该是循环中使用的同一个变量中的递增值。于是经过分析,可以得出如下的逻辑:
1 | int length = strlen(flag); |
可以看到,这些检测并不能确认一个具体的值,而是【将数值限制在了某个范围内】。所以后面的程序逻辑极有可能都是【限制数值的取值】。后面的逻辑逆向如下:
1 | // third check |
根据前6个check,我么能够知道如下信息:
- flag长度为0x26
- flag为
dice{XXXXXXXXXXXXXX}的形式 - 从中间开始,flag被打乱排序进行检测
然而如果我们仅用前六个逻辑,使用z3会计算出非常大量的答案,根本没办法确认哪个才是正确答案。在这六个逻辑后,还有最关键的第七个maze_step,也就是前面未提到的走迷宫函数。显然,需要配合迷宫才能完成最后的约束。
阶段三:迷宫绕路
在进入迷宫前,会将flag中间的数值(总共32字节)取出,并且打乱后重组。在逆向这个迷宫函数的时候,发现迷宫函数本身有点怪异。与其他CallFunc不同,迷宫函数本身非常大,功能也很多:
1 | _QWORD *__fastcall maze_step(a) |
可以看到,当前函数中,既有创建地图的逻辑,又有初始化地图的逻辑,移动的逻辑,以及检查逻辑。
并且在此时,Block中出现了三个不同的数据表:
1 | [0x7f4477c54160]Block[0xd5a]: |
结合程序逻辑,我们能够大胆猜测,这个函数的运行逻辑如下:
- 先尝试初始化maps
- 读取
flag[i],然后从三个不同的表steps1,steps2,steps3中取出对应的数字 - 根据数字,得到当前的maps的前进路径
- 最后检查的时候,获取当前的坐标
通过进一步分析maze函数和blocks,能够得知以下信息:
- 起点为(0x40,0x40)
- 终点为(0x45,0x8)
- 每个flag会强迫当前迷宫前进三步,这意味着这个迷宫必须要在96步中完成
- 每一步都不能碰到数字
-1
一开始,我尝试过直接使用最短路径来计算如何前往目的地。毕竟大多数时候,这种逆向题目都会将最短路径作为唯一解。我尝试过使用BFS找最短路径,然而最后得到的路径居然只需要89步,而不是题目要求的96步。
简单分析了一下,我发现这个题目中,总共有9种前进模式。除了常见地上下左右,还能斜着前进,以及原地不动。于是我修改成上述地样子,指定必须在规定的步数内完成:
1 |
|
然而我打印了路径后发现,算法得到的路径只是先原地打转,然后再直接使用最短路径前进如果答案真的这样做,那可能的情况也太多了。在朋友地提示下,我打印出了当前执行地地图,地图大致如下:
在这个地图片段的最下方,有一个像是L的地方。如果用算法的话,它总是会这样前进:
然而,根据一般逆向题的逻辑,这里的路径应该是要长成这个样:
再三纠结了以下,我尝试手动走这个迷宫,并且在拐角处尽可能地转弯而不是走斜线,发现正好在96步完成了迷宫。然而,正如我们前文提到的,我们的前进方向会受到前面三个表的限制,他这个前进模式如下:
1 | char* steps[] = {step1, step2, step3}; |
举个例子:当我们的c取值为0的时候,step1[0]的值为0,steps2[0]的值为0。在我们获得了正确前进路线的情况下,这里尝试一口气使用三个前进方向来反向限制当前的输入。根据这个逻辑,可以写出如下的代码:
1 |
|
在代码中的targets即为一个由三个步子构成的前进方向方向。在脚本的配合下,走迷宫走到终点后能够得到一个这样的对应关系:
1 | targets = [ |
可以看到,即使尝试利用路径限制,每一个flag的取值也不是固定的。最终,我们将这一个约束条件也加入,可以得出如下的解题脚本:
1 |
|
最终在这个约束下,能够求得唯一的flag。
总结
关于题目回顾
在看到官方给出的出题脚本之后,感觉依然没办法判断具体是哪种语言,感觉可能是一种叫做racket的编程语言。这种编程语言的思想其实很有意思,假设根据这种程序的编译结果来看,这些Block之间其实感觉是可以并发执行的。之前也和朋友讨论过,这种设计可能会导致cache命中出现问题,但是好像又增加了并发的可能。以后有空的话可以进一步学习这种有趣的编程语言
关于做题总结
这一次做题比上一次花了更长的时间。虽然一直都是做逆向出身,也做过逻辑特别复杂的题目,但是好像每次我都只能应付很小类型的题目。这次的题目其实回头看,当时挣扎的点都正好就是题目的难点:
- 是否应该把Block dump下来?还是考虑用angr符号执行来做
- 是否应该使用Edge将Block串联起来?这个过程会不会浪费很多时间?参数的顺序又是怎么样子的呢?
- 未初始化情况下Dump的Block似乎没有参考价值?是不是不应该这么做呢(后来想到了可以再最后阶段进行dump)
- 如此多的约束仍然求不出答案(当时没考虑maze的约束)是不是解题思路不对呢?
- maze这么长的迷宫,果然还是应该用算法做吧,但是最短路径总是算的不对(最后直接使用手走迷宫)
每次迷茫的时候,其实心里都有正确答案,却一直在担心没有找到最优解而没有做下去。看起来比起pwn题,逆向更加需要比较坚定的信念和定力,也许确实更加考验做题人的精神力(笑)
]]>




























































































































































































































































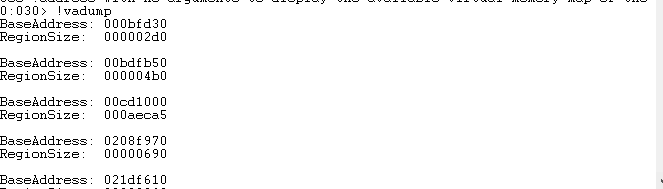





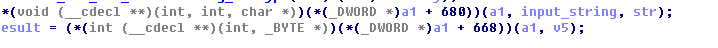
























































































































































































































































{kind=link}